Goodbye Kubernetes
Published on , 1697 words, 7 minutes to read
Well, since I posted that last post I have had an adventure. A good friend pointed out a server host that I had missed when I was looking for other places to use, and now I have migrated my blog to this new server. As of yesterday, I now run my website on a dedicated server in Finland. Here is the story of my journey to migrate 6 years of cruft and technical debt to this new server.
Let's talk about this goliath of a server. This server is an AX41 from Hetzner.
It has 64 GB of ram, a 512 GB nvme drive, 3 2 TB drives, and a Ryzen 3600. For
all practical concerns, this beast is beyond overkill and rivals my workstation
tower in everything but the GPU power. I have named it lufta, which is the
word for feather in L'ewa.
Assimilation
For my server setup process, the first step it to assimilate it. In this step I get a base NixOS install on it somehow. Since I was using Hetzner, I was able to boot into a NixOS install image using the process documented here. Then I decided that it would also be cool to have this server use zfs as its filesystem to take advantage of its legendary subvolume and snapshotting features.
So I wrote up a bootstrap system definition like the Hetzner tutorial said and
ended up with hosts/lufta/bootstrap.nix:
{ pkgs, ... }:
{
services.openssh.enable = true;
users.users.root.openssh.authorizedKeys.keys = [
"ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIPg9gYKVglnO2HQodSJt4z4mNrUSUiyJQ7b+J798bwD9 cadey@shachi"
];
networking.usePredictableInterfaceNames = false;
systemd.network = {
enable = true;
networks."eth0".extraConfig = ''
[Match]
Name = eth0
[Network]
# Add your own assigned ipv6 subnet here here!
Address = 2a01:4f9:3a:1a1c::/64
Gateway = fe80::1
# optionally you can do the same for ipv4 and disable DHCP (networking.dhcpcd.enable = false;)
Address = 135.181.162.99/26
Gateway = 135.181.162.65
'';
};
boot.supportedFilesystems = [ "zfs" ];
environment.systemPackages = with pkgs; [ wget vim zfs ];
}
Then I fired up the kexec tarball and waited for the server to boot into a NixOS
live environment. A few minutes later I was in. I started formatting the drives
according to the NixOS install
guide with
one major difference: I added a /boot ext4 partition on the SSD. This allows
me to have the system root device on zfs. I added the disks to a raidz1 pool
and created a few volumes. I also added the SSD as a log device so I get SSD
caching.
From there I installed NixOS as normal and rebooted the server. It booted normally. I had a shiny new NixOS server in the cloud! I noticed that the server had booted into NixOS unstable as opposed to NixOS 20.09 like my other nodes. I thought "ah, well, that probably isn't a problem" and continued to the configuration step.
Configuration
Now that the server was assimilated and I could SSH into it, the next step was to configure it to run my services. While I was waiting for Hetzner to provision my server I ported a bunch of my services over to Nixops services a-la this post in this folder of my configs repo.
Now that I had them, it was time to add this server to my Nixops setup. So I
opened the nixops definition
folder and
added the metadata for lufta. Then I added it to my Nixops deployment with
this command:
$ nixops modify -d hexagone -n hexagone *.nix
Then I copied over the autogenerated config from lufta's /etc/nixos/ folder
into
hosts/lufta and
ran a nixops deploy to add some other base configuration.
Migration
Once that was done, I started enabling my services and pushing configs to test them. After I got to a point where I thought things would work I opened up the Kubernetes console and started deleting deployments on my kubernetes cluster as I felt "safe" to migrate them over. Then I saw the deployments come back. I deleted them again and they came back again.
Oh, right. I enabled that one Kubernetes service that made it intentionally hard to delete deployments. One clever set of scale-downs and kills later and I was able to kill things with wild abandon.
I copied over the gitea data with rsync running in the kubernetes deployment.
Then I killed the gitea deployment, updated DNS and reran a whole bunch of gitea
jobs to resanify the environment. I did a test clone on a few of my repos and
then I deleted the gitea volume from DigitalOcean.
Moving over the other deployments from Kubernetes into NixOS services was
somewhat easy, however I did need to repackage a bunch of my programs and static
sites for NixOS. I made the
pkgs tree a bit more
fleshed out to compensate.
Reboot Test
After a significant portion of the services were moved over, I decided it was
time to do the reboot test. I ran the reboot command and then...nothing.
My continuous ping test was timing out. My phone was blowing up with downtime
messages from NodePing. Yep, I messed something up.
I was able to boot the server back into a NixOS recovery environment using the kexec trick, and from there I was able to prove the following:
- The zfs setup is healthy
- I can read some of the data I migrated over
- I can unmount and remount the ZFS volumes repeatedly
I was confused. This shouldn't be happening. After half an hour of troubleshooting, I gave in and ordered an IPKVM to be installed in my server.
Once that was set up (and I managed to trick MacOS into letting me boot a .jnlp web start file), I rebooted the server so I could see what error I was getting on boot. I missed it the first time around, but on the second time I was able to capture this screenshot:
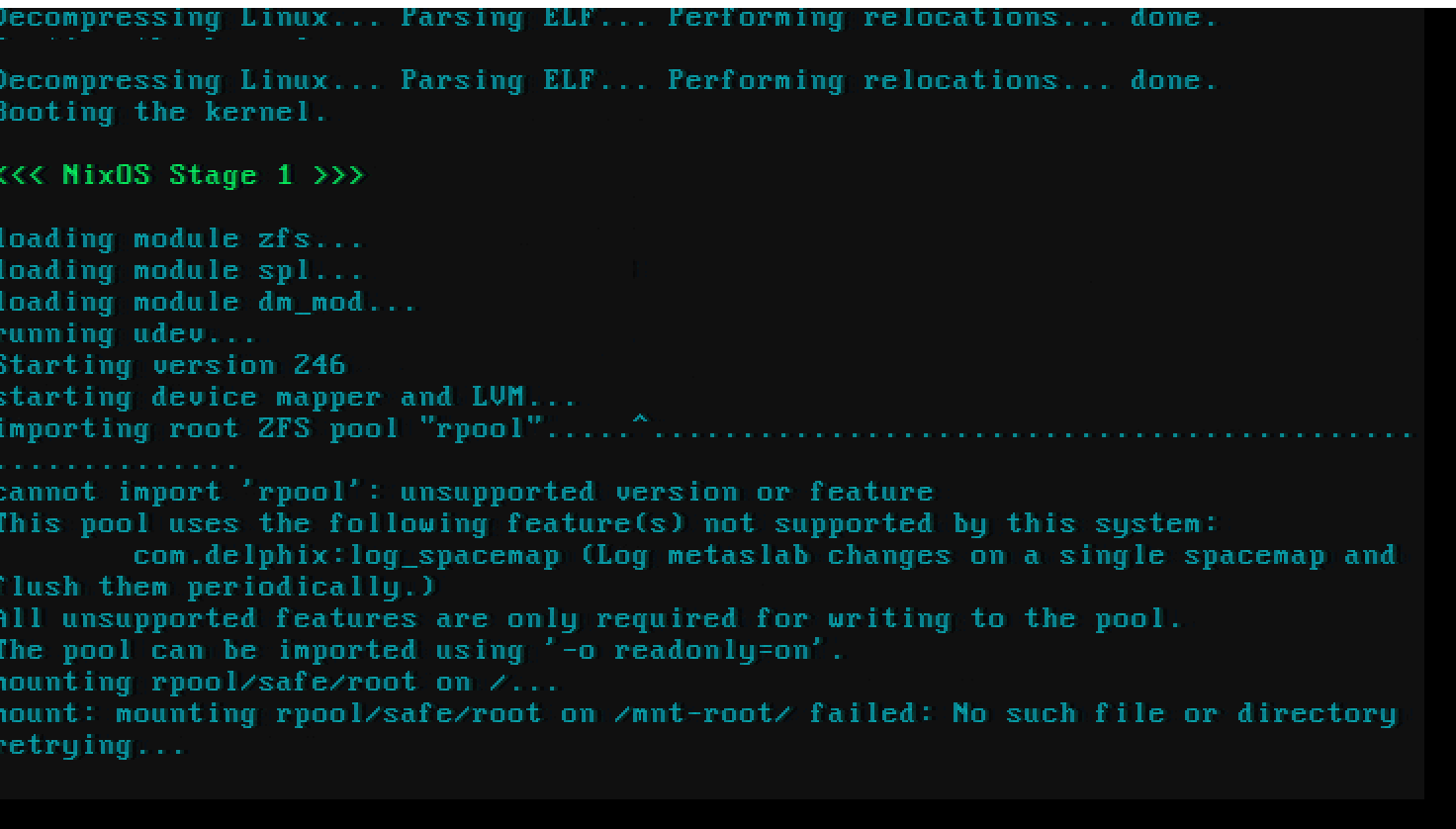
Then it hit me. I did the install on NixOS unstable. My other servers use NixOS 20.09. I had downgraded zfs and the older version of zfs couldn't mount the volume created by the newer version of zfs in read/write mode. One more trip to the recovery environment later to install NixOS unstable in a new generation.
Then I switched my tower's default NixOS channel to the unstable channel and ran
nixops deploy to reactivate my services. After the NodePing uptime
notifications came in, I ran the reboot test again while looking at the console
output to be sure.
It booted. It worked. I had a stable setup. Then I reconnected to IRC and passed out.
Services Migrated
Here is a list of all of the services I have migrated over from my old dedicated server, my kubernetes cluster and my dokku server:
- aerial -> discord chatbot
- goproxy -> go modules proxy
- lewa -> https://lewa.within.website
- hlang -> https://h.christine.website
- mi -> https://mi.within.website
- printerfacts -> https://printerfacts.cetacean.club
- xesite -> https://xeiaso.net
- graphviz -> https://graphviz.christine.website
- idp -> https://idp.christine.website
- oragono -> ircs://irc.within.website:6697/
- tron -> discord bot
- withinbot -> discord bot
- withinwebsite -> https://within.website
- gitea -> https://tulpa.dev
- other static sites
Doing this migration is a bit of an archaeology project as well. I was continuously discovering services that I had littered over my machines with very poorly documented requirements and configuration. I hope that this move will let the next time I do this kind of migration be a lot easier by comparison.
I still have a few other services to move over, however the ones that are left are much more annoying to set up properly. I'm going to get to deprovision 5 servers in this migration and as a result get this stupidly powerful goliath of a server to do whatever I want with and I also get to cut my monthly server costs by over half.
I am very close to being able to turn off the Kubernetes cluster and use NixOS for everything. A few services that are still on the Kubernetes cluster are resistant to being nixified, so I may have to use the Docker containers for that. I was hoping to be able to cut out Docker entirely, however we don't seem to be that lucky yet.
Sure, there is some added latency with the server being in Europe instead of Montreal, however if this ever becomes a practical issue I can always launch a cheap DigitalOcean VPS in Toronto to act as a DNS server for my WireGuard setup.
Either way, I am now off Kubernetes for my highest traffic services. If services
of mine need to use the disk, they can now just use the disk. If I really care
about the data, I can add the service folders to the list of paths to back up to
rsync.net (I have a post about how this backup process works in the drafting
stage) via borgbackup.
Let's hope it stays online!
Many thanks to Graham Christensen, Dave Anderson and everyone else who has been helping me along this journey. I would be lost without them.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: