XeDN on Tigris
Published on , 3325 words, 13 minutes to read

It's been a while since I did another "Xe alt-universe backend engineering" post. I think the last one was about how I switched to a static site generator. I've done the groundwork for some exciting things since then, but today I'm gonna explain a huge upgrade I made to XeDN. XeDN.

XeDN is my CDN backend service that I originally wrote in a weekend to see if it was possible to make something decent in 48 hours. It's essentially a caching proxy to Backblaze B2, just with a bunch of nodes all over the globe to hack the speed of light in my favor. Well, you could think about it as one, because now that part of XeDN is being deprecated in favor of something that I wish I had ages ago: Tigris Object Storage.
XeDN is many things, but the main thing that it's become is a burden to maintain. I like having my own infrastructure power my website as much as humanly possible, but at some point something's got to give. I've been running into a lot of subtle issues with XeDN that I'll get into more details about as this article goes on.
By adopting Tigris into my infrastructure, I can rip out the biggest part of XeDN and make it someone else's problem: the caching layer. I'll get into more detail about how XeDN's cache layer used to work, but the main benefit for me is that I don't have to worry about it or baby it anymore.
Tigris? What is that?
Tigris Object Storage is one of the most exciting things I've seen in a long time for a pretty boring product: storing data somewhere else and being able to get it back when you need it. Tigris lets you upload your files in Toronto, have them get stored in Toronto, and reached from Toronto. All without having to worry about going out of your way to put the data in Toronto.
When I made XeDN, I wanted to have something like this and even sketched out the ideas for making it, but I never got around to actually doing it. I'm glad that Tigris exists because it means that I don't have to do it myself.
The really cool part about Tigris though is that they implemented that one paper Apple made about how iCloud works. This allows Tigris to store your data in an actually global way, with durable backups and regional caching on demand.
As I said in a corpo blogpost, one of the biggest lies in the cloud has to do with how AWS S3 stores your data on disks (or hyperputers, or whatever they do over there, I'm assuming there's spinning rust in the stack somewhere). When you upload an object to an S3 bucket, 9 times out of 10, you are uploading those bytes to a nondescript building in Ashburn, Virginia.
One of my favorite SRE interview questions to ask to people is "The datacenter got hit by a meteor and is totally obliterated off of the face of the earth and took most of the SRE team with it. Your first day is today. What actions do you take to maximize uptime?"
If I was working on a product where everything was shoved into us-east-1, I'd probably say that we'd be so incredibly fucked that it's not even funny. The worst part would be the S3 uploads.
That one Apple paper that everyone wishes they could implement
When Apple made their current version of iCloud, they designed its storage backend so that us-east-1 can get hit by a meteor without affecting the availability of files. Sure, society as a whole would have a very hard time functioning in the wake of this (I guarantee you every big website that runs on AWS would all have massive downtime just from the object storage alone, not to mention the massive number of disks that they house), but iCloud uploads would be able to be fine. The reason why is that iCloud uploads are spread out between multiple logical object storage providers, as well as some level of caching on their own servers.
This means that Apple buys object storage from Google, Amazon, Microsoft, and Oracle and stores heavily encrypted copies of your cat pictures all across the globe. Many companies all over the world would have to have problems all at once for the iCloud availability to notice.
Tigris Data actually implemented Apple's QuiCK paper and has made the results available with an API compatible with your S3 client of choice. The cool part about how they did this means that if a user is uploading a file in Berlin, then the data will go to he Frankfurt datacenter automatically. The data will be stored in Frankfurt by default until and unless the data is requested from someone in Ottawa, then the data will be copied to Toronto for the user and served from there for the next requestor.
XeDN's architecture
XeDN didn't have to exist, but I decided to make it exist anyways. XeDN is a caching proxy to Backblaze B2. I used to use a commercial product that had zero-rated access to files stored in Backblaze B2 buckets, and the architecture of XeDN is mostly intended to replicate that but with caching on local storage instead of using that commercial product.
Essentially, the infrastructure looks like this:
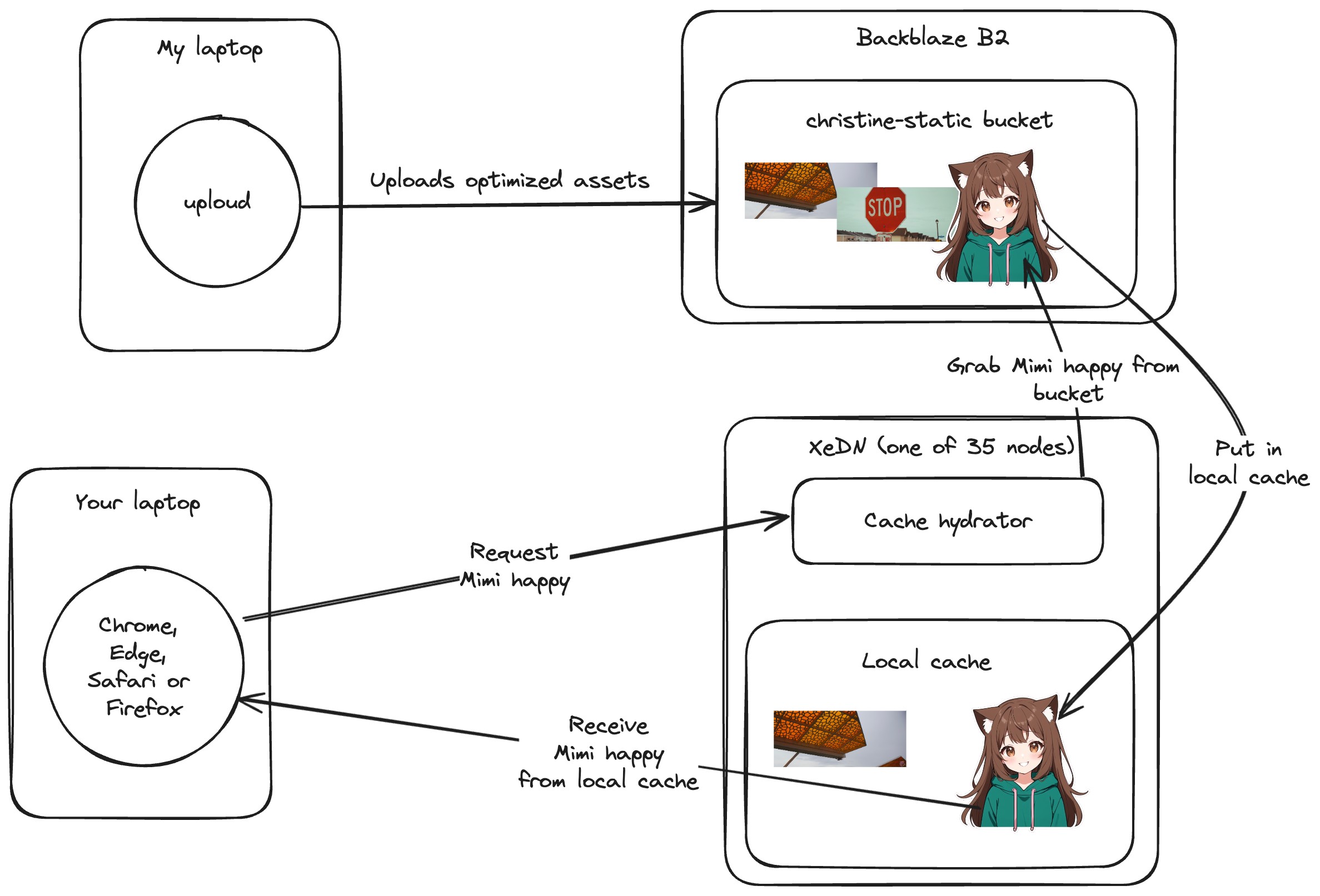
My laptop optimizes and uploads assets to the bucket, and then XeDN caches the assets people actually use in that region. This means that if you're in Berlin and nobody else has requested an asset from Berlin before, it'll take a moment to get the asset from wherever Backblaze B2 is storing it. If you're in Berlin and someone else has requested the asset from Berlin before, then you'll get the asset from the local cache.
XeDN's cache layer is a giant key-value store with BoltDB that's on an SSD. Caching is a surprisingly complicated bit of software to write. When you cache things you need to read them from the source, write them to the destination, and then read them from the destination if they're already there.
I use a program I made called uploud to auto-crunch images and upload the optimized versions to cloud storage. Once those files go into the bucket, they are available for XeDN to request and cache them. XeDN assumes that the bucket is append-only, so I just keep uploading files on the end and everything is hunky-dory.
Except there are times when I need to go back and change the contents of the bucket. Most recently, I wanted to update Mimi's stickers from the older attempts I made at the beginning of 2023 to the more modern stickers that she uses today:

Either way, I could clear out old files by manually poking the internal "delete this cached file" endpoint, but that didn't scale well. For highly-requested files, this means that the XeDN node would delete the file...and then immediately re-cache the file because someone asked for it.
I also royally fucked up when designing the caching logic because I made it extend the cache lifetime of any object by a week when it was requested. This means that some of the most commonly used assets have a lifetime in the thousands of years, and because I was using BoltDB as the backing store, I effectively had the entire state of the world in a global mutex that allowed one person to read each file at once.
Adding Tigris in
Adding Tigris to the XeDN fly.toml was trivial:
[[statics]]
url_prefix = "/file/christine-static"
guest_path = "/"
tigris_bucket = "xedn"
This mounts the Tigris bucket xedn on the path /file/christine-static, so when you request anything from the CDN bucket, it'll be routed to Tigris instead of the local cache. It also means that I can keep the same URL structure for the files that I've already uploaded. I have too many posts and projects that rely on the existing URL structure to change it now.
Sticker resizing
Since XeDN has a cache of all of the popular files in the bucket, I've made things that use that cache to its advantage. Whenever I put one of these conversation snippets in a post:
It ends up embedding this URL into the generated HTML:
https://cdn.xeiaso.net/sticker/aoi/grin/256
This is a URL that XeDN handles by resizing the original sticker to 256x256 and serves it in the right format according to what your browser accepts. This allows me to automatically embed stickers in my posts without having to worry about clients that can't understand the <picture> element, and it allows XeDN to automatically pick the right format for the browser.
{kind=link}
Before I made changes, here's how sticker compression worked:
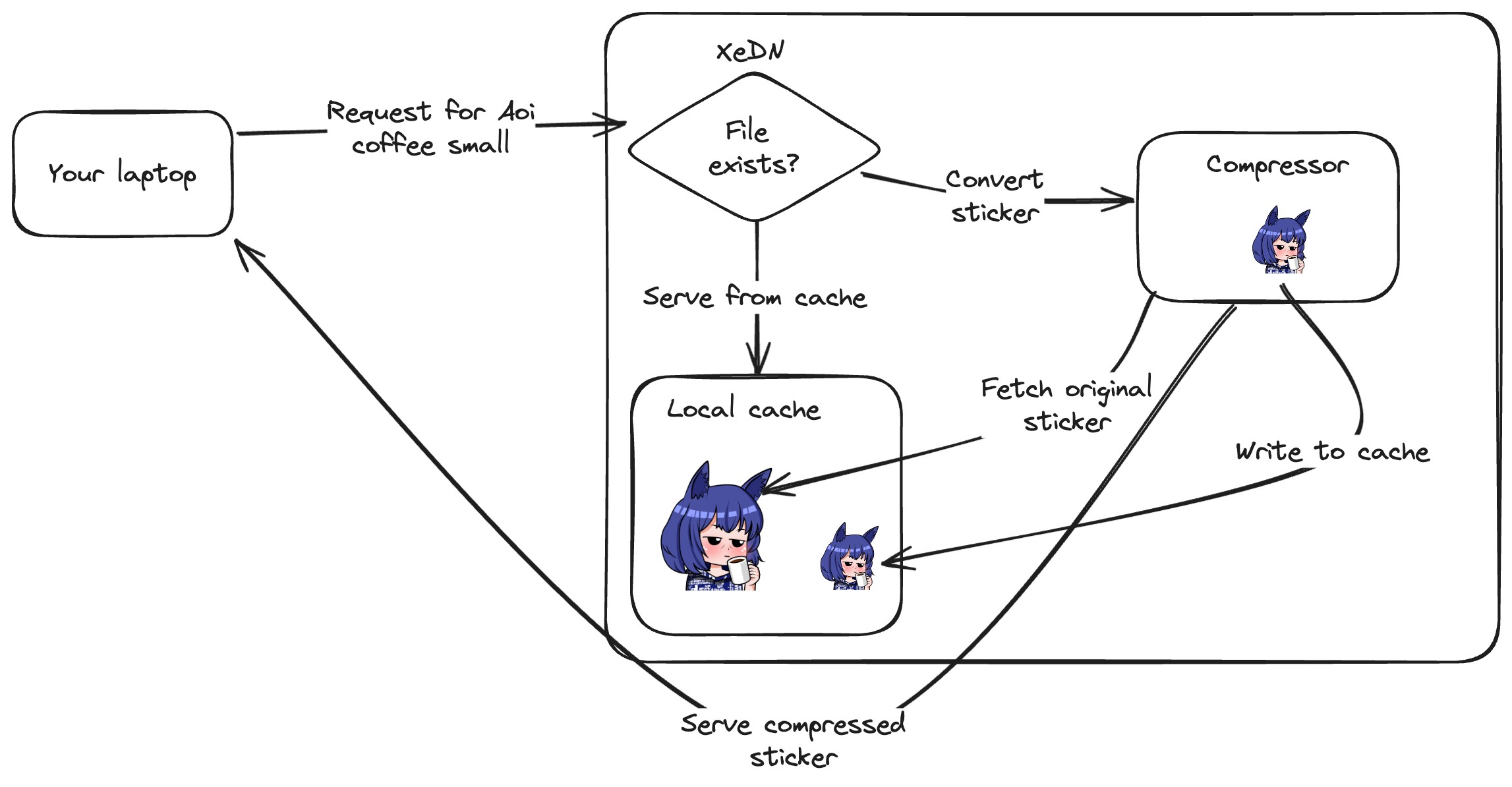
This is built on top of the local cache, and it's a feature that I'm going to have to maintain in order to keep the site working. The local cache is going away, so I needed to rewrite this feature to use Tigris instead.
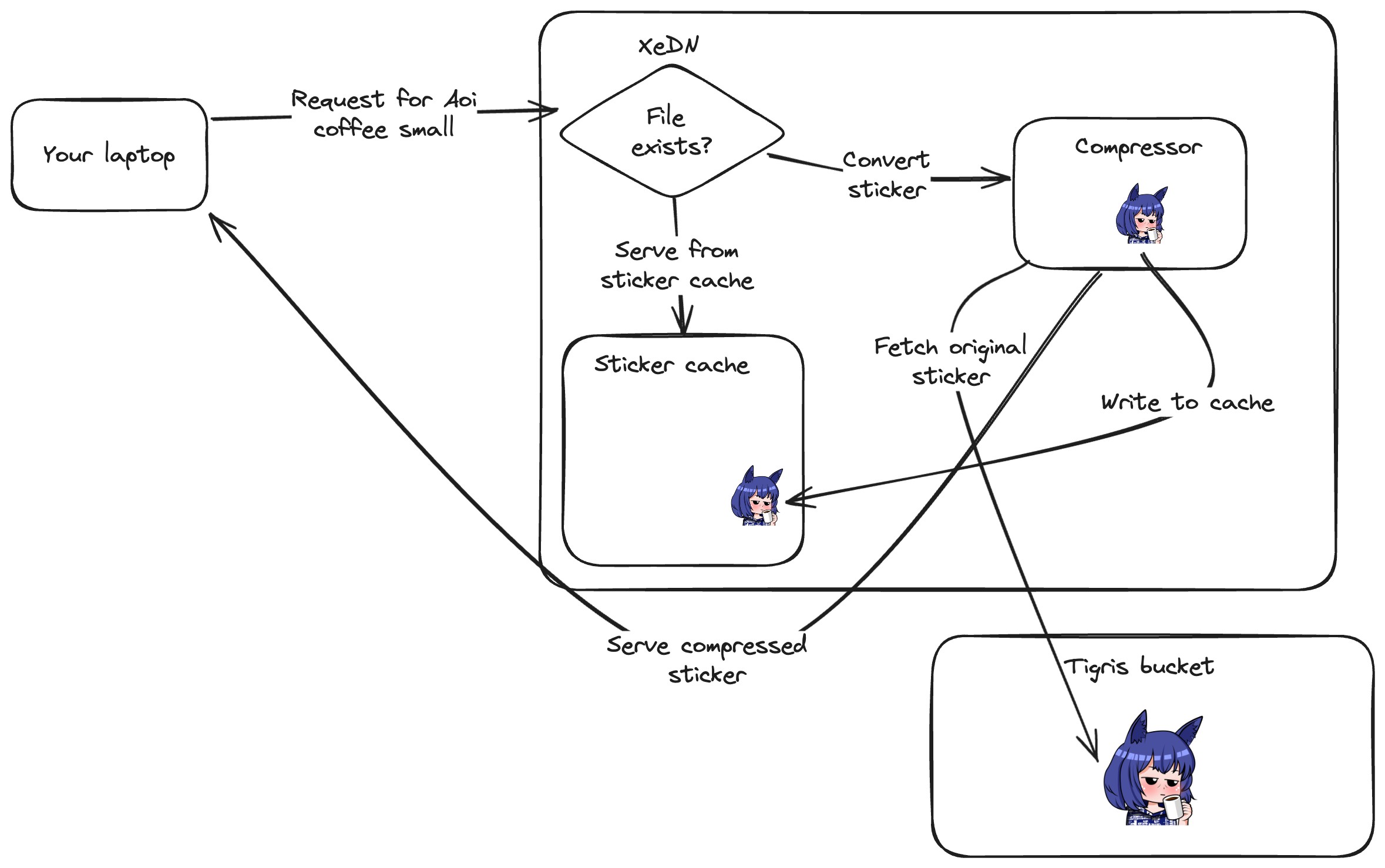
However, since I'm just going to be having most of the same behavior of XeDN's local cache, I can cheat and fetch the sticker URL from Tigris and then process it. This means that I can keep the same URL structure and not have to change anything in the posts that I've already written.
So the only thing that's changed is that stickers are fetched from Tigris instead of being escrowed through the local cache:
Avatar generation
One of the things I built on a stream is an avatar generator like Gravatar powered by Stable Diffusion. It generates hopefully useful 256x256 avatars based on a prompt hallucinated from a MD5 hash. To embed an avatar for a user with an email address, you can use this code snippet in your website's frontend code:
<img
className="w-32 h-32"
src={`https://cdn.xeiaso.net/avatar/${md5sum(user.email)}`}
/>
Then in a moment a brand new image will come back that you can use as a placeholder for your needs. Here's an example.

This is also built on top of the XeDN cache, but the pro gamer move is to take advantage of one of the killer features of the integration of Fly.io's HTTP proxy and Tigris: files not found in Tigris will fall-through to your app.
This let me load all of the existing images in the local cache into a Tigris bucket and then if the request hits XeDN, upload an avatar to take its place.
Why change the URLs when you can maintain compatibility with the old URLs? Cool URLs don't change.
XeDN is more reliable now
For most of you reading this, XeDN is something that you don't really integrate with (and realistically, you probably shouldn't do that without contacting me beforehand). You just visit my website and the assets are served from XeDN. You don't really care about the backend, and that's fine.
The biggest thing you are going to notice is that video is going to work more reliably. Sometimes the half-baked caching scheme would cache half-complete downloads of video chunks, which would cause the video to not play because processing half a chunk of video gets you corrupt data. This is not the user experience I want.
I also don't really need to worry about the chunk size of my video because my caching mechanism doesn't rely on reading all of the data into RAM at once. That was one of the biggest reasons why I've had to be so stingy with my bitrate when I upload video to my website, if I didn't make the bitrate low, I could make the entire XeDN constellation fall over every time I published a video, putting those half-baked chunks in the cache.
One of the things that was really annoying about the existing architecture of XeDN is that I had to have more caching nodes in more places to cheat the speed of light away. Now that Tigris is a thing, I could get away with only a single node in Toronto to handle everything that isn't in Tigris. I think I'm going to settle on three nodes in Seattle, Toronto, and Frankfurt. Either way, it's a huge reduction in the number of XeDN nodes, which means that there's fewer ways things can fail. The rest of the global availability can be outsourced to Tigris.
I'm going to write up how I plan to replace my image optimizer and uploader uploud with something a bit more robust eventually, but I can only write so much about it until it's actually implemented.
I'm so glad I can rip out a giant part of the XeDN codebase and make it someone else's problem. People have been asking me what they should do to store Mastodon uploads on the cheap, and I was genuinely considering making an improved version of XeDN for that (probably with my own S3 API handler family), but now that Tigris exists and does the job better, I don't have to do that.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: xedn, tigris, s3