Reflection is cooked
Published on , 3171 words, 12 minutes to read

Generative AI is in its Cambrian Explosion phase. So many people are taking the models and messing around with them in so many ways to try and see if they can make something work. There's just one problem: how do you tell if a model is good or not without actually setting it up and using it?
One of the biggest points of comparison is the Elo score that each model gets when it's added to the LMSYS Chatbot Arena leaderboard. This is generally seen as a consistent way to evaluate models, but it's kinda costly to do these evaluations and takes a fairly long time to converge on a ranking that "makes sense". My favorite model Hermes 3 70b isn't currently on the leaderboard (probably because it was released like two weeks ago), but the model it's based on (Facebook's Llama 3.1 70b Instruct model) currently ranks 16th.
As a way for researchers to perform epic rock ballads in the form of expensive research that results in papers on how their models and training methodologies compare on benchmarks. These benchmarks allow you to get scores that are easy to publish, but also easy to validate. These benchmarks have names like AGIEval, Hellaswag, Winograde, and MMLU-PRO. They allegedly test the performance of the models for doing human-useful tasks such as completing sentences, general knowledge (the kind that the Gaokao, law school bar exam, and SAT test), and common sense reasoning capabilities. These benchmarks align with what researchers think large language models are useful for.
The benchmarks are made public so that you can run them locally; but as a side effect that means that the data models are being tested on is inevitably in the dataset that they are trained on. This usually means that you need to go through painstaking effort raking through your datasets to try and purge out the test data from your training set.
This is not an easy task, but there's a confounding factor at play: AI company value is determined by hype. Hype is determined by benchmark scores and initial reactions (which are always higher due to the placebo effect because it's new). Getting more hype means more investors want to talk and give your AI startup more money, which you desperately need in order to run your expensive AI training experiments.
So that benchmark data is publicly available and you're normally supposed to remove it from your training datasets. What if you just didn't? Pretraining on the test set is all you need after all. What could go wrong?
Reflection
In the last week, Otherside AI announced their new model Reflection 70b, which they claimed is based on Facebook's Llama 3.1 70 billion parameter (70b) open-weights large language model. The main gimmick is that Reflection is trained on "chain-of-thought" prompting where it gets the model to think out loud to itself about a request before answering a question. This is intended to mimic how people think to themselves about a complicated request before giving a response.
This is one of those psychology things where it's really complicated to explain, but really easy to understand when you see it in action. As such, here's what happened when I asked it to add 2 and 2:
Yeah, not the most ideal result, but this also shows off the other key gimmick of the model, the "reflection" blocks. While the model is "thinking" about its responses, it can emit a reflection block for realizing an error and correcting it mid-thought. I'm gonna be totally honest that I'm really not an expert in this stuff and I'm not sure if this actually works beyond the placebo effect of trying a different way of using the model. I've been told that chain-of-thought prompting is how Claude Artifacts work, but again I haven't done enough research to speak confidently about this.
Maybe this points towards the idea that large langle mangles don't actually understand the nuance or context of human language and are just pattern regurgitators. This would imply that English and other languages are actually a lot simpler than any of us think they are and the scale AI models operates is about as complicated as it can get. I have seen people claim that Reflection's outputs are some of the best they've seen, but I don't know how placebo-poisoned they are in the process. That's probably a psych study for a different day.
Either way, they claimed to do well in benchmarks:
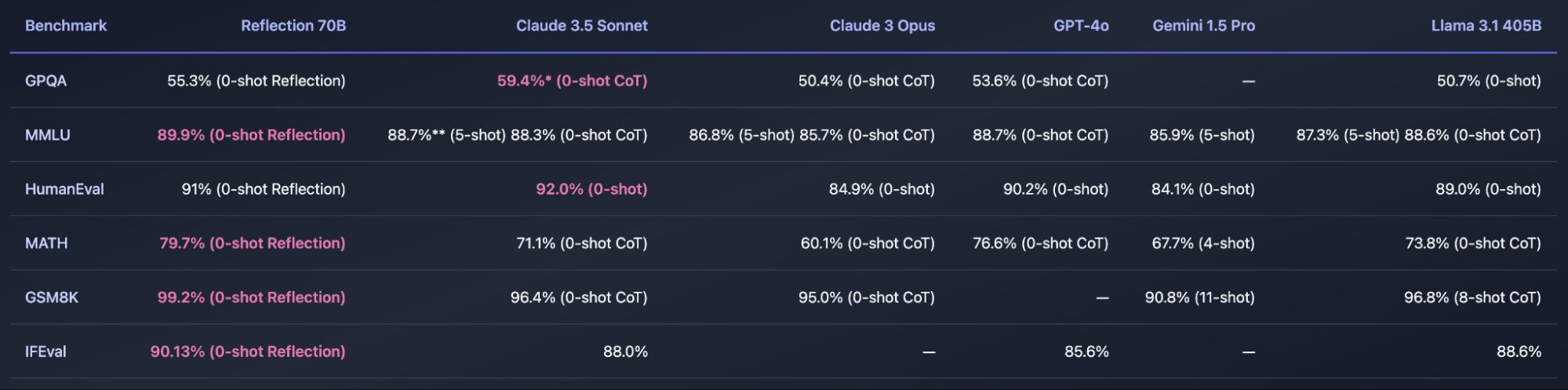
Image downloaded from Matt Shumer on X - source
Assuming this is legitimate, this is a groundbreaking discovery. Actually, no, groundbreaking isn't a strong enough word for this. If this panned out, this is an earth-shattering discovery that fundamentally changes the scale required for getting frontier model class performance without having to pay out for frontier model class hardware.
Why it's such a huge deal
In order to fully appreciate the magnitude of this, let's go over how you determine the hardware needed to run a given large language model. A machine learning model is functionally a giant bag of numbers of a certain size, usually IEEE-754 float16 numbers. A 70 billion parameter model requires you to have at least 140 gigabytes of video memory (VRAM) to load the model at all.
However, it's not just conventional system memory that you can get for fairly cheap. It's video memory on a GPU. VRAM is usually hard-soldered onto a GPU with no way to upgrade it, so once you buy a GPU, you're stuck with however much memory you have. Getting more memory means you need to buy more GPUs. As a result, enterprise GPUs with high memory amounts are so much in demand that three year old models have backlogs of more than a year from time of purchase to time of shipment.
Not to mention, you don't just need to load the model weights, you need to have the memory space to inference the models. The great part about this is that it's difficult to figure out how much memory you'd actually need without testing it.
In general back when smaller context window models were common, I used the head math estimate of adding 20-40% more memory on top of the weights. Here's how this matches with reality:
| Model | Weights (GB) | Estimate VRAM (GB) | Actual VRAM (GB) |
|---|---|---|---|
| Hermes 3 8B Q4 @ 4k | 4.7 GB | 6.5 GB | 6.7 GB |
| Hermes 3 70B Q4 @ 4k | 39 GB | 50 GB | 44 GB |
In general, the attention window takes up a few gigabytes of video memory, but the horrifying part is that as the context window size increases, the amount of video memory required increases exponentially. Here's some examples:
| Model | VRAM needed |
|---|---|
| Hermes 3 8B Q4 @ 4k | 6.7 GB |
| Hermes 3 8B Q4 @ 8k | 11 GB |
| Hermes 3 8B Q4 @ 16k | 18 GB |
| Hermes 3 8B Q4 @ 32k | 31 GB |
| Hermes 3 8B Q4 @ 64k | 18 GB |
| Hermes 3 8B Q4 @ 128k | 31 GB |
| Hermes 3 8B Q4 @ 256k | 58 GB |
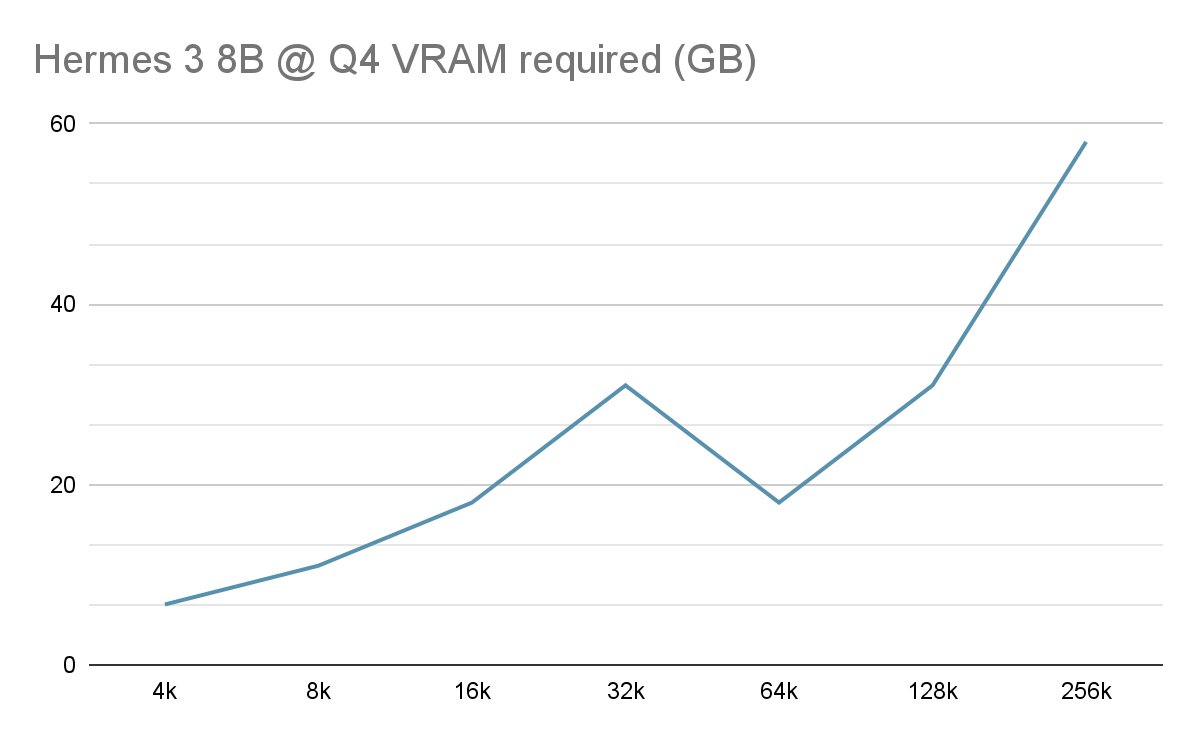
There is a dropoff in VRAM usage when you go from 32k to 64k tokens in your context window, I'd assume that has something to do with flash attention or any of the improvements made to it over the years. Either way, you get the point. More context = exponentially more vram required.
If the AI startup behind Reflection is onto something, this means that you need less hardware to get the same quality as frontier models without having to build out a gigawatt supercluster of GPUs that you can't buy anyways. This means we're one step closer to having something at the utility and scale of GPT-4 that can be run on unmodified consumer hardware.
Based on the information we all knew at the time of its announcement, yeah it's a big thing and it got hyped up by people on X and people in the media. I'm not gonna shit on the media here. Reporting new events and discoveries is their job. I'm going to good faith assume that they consulted with an expert to see if the vibes were off; but as an artificial intelligence computer toucher, that announcement was exciting. I'd love to have something totally local, totally private, but also capable of helping with whatever task I'd want it to.
If the same concept was able to scale down, this means that models like Apple Intelligence could actually be more capable on your phone next year than they are on servers today. To say this would be a game changer for AI utility and deployment would be another understatement so large I lack the capacity to explain it in English.
Nobody would be stupid enough to torch their reputation in a reputation driven hype bubble to win magic internet points and venture capital funding, right?
The cracks form
When the weights were dropped on HuggingFace, they were downloaded as fast as their servers allowed. Initial results were not promising. People found that it somehow performed worse than Llama 3.1 70b out of the gate.
This should have been impossible. If the Reflection fine-tuned model is a categorical improvement on the base model, then every benchmark should have a higher result than the base model. I'm not even talking about human vibe evaluation, I'm talking about the gameable benchmarks like Hellaswag, AGIEval, and StrawberryLetterCountEval.
The CEO of the AI company claimed they fucked something up in the process of uploading the weights. Which is fair enough, git isn't exactly the most intuitive program to use, and LFS support in Git is a massive, massive hack. As a way for people to evaluate the model, they opened up a private API endpoint so that a few select researchers could run their benchmarks. They also were soliciting help setting up a torrent, which made me have many lols.
One of the researchers that got access to that private API claimed that the model was not at the level they claimed it was in the announcement. They were also cagey on claiming that Reflection was any good because it was difficult to impossible to validate that the model they were running was actually the model that it claimed it was.
Everything changed when they opened that private API to anyone via OpenRouter. People instantly were able to tell that it was Anthropic's Claude model, down to the level of search-and-replace filtering out the word "Claude" from responses.
Amusingly enough, their neutering of Claude via Reflection's system prompt caused Claude to perform remarkably worse than it does without it. A friend of mine even called it as Claude a day before anyone else. They were so right in retrospect that it kinda hurts.
Allegedly at some point the Reflection team switched the model out to GPT-4o behind the scenes, but at this point I kinda lost interest in tracking the details and don't really have anything else to say. The damage was done. The giant impossible breakthrough for local AI models was a puff of hot air.
Reflection is cooked
So now as the ash settles, I'm left with a big bag of floating point numbers on my MacBook's SSD that won't really be useful for anything but writing what remains of this article. At least it allegedly can count the number of r's in the word strawberry:
Maybe the team behind Reflection will end up making great models, but I just can't trust their claims anymore. If they do actually make something decent out of the ashes of Reflection I'll try it, I guess, but I'm not holding my breath. It looks like some AI companies reached out to them to help with the logistics of training and distributing the weights for a "redo". I'm just gonna wait this one out. I'd absolutely love to be proven wrong here. I know there is a lot of theoretical performance still waiting on the table, but thanks to this I'm going to be a lot more skeptical when I see new breakthroughs in the future.
For now though, I want that disk space back:
$ ollama rm reflection
Author's note: I tried to make the Reflection snippets as readable as possible. Some combination of my formatter, MDX, and Tailwind are fighting me hard. Should this style of chain-of-thought prompting take off, I plan to develop inline speech bubble components to help represent the different stages of chain-of-thought inference. I don't suspect it will, so I haven't taken the time to do that yet.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: