Rebuilding my homelab: Suffering as a service
Published on , 12856 words, 47 minutes to read
With additional Kubernetes mode!

I have a slight problem where I have too many computers in my office. These extra computers are my homelab, or a bunch of slack compute that I can use to run various workloads at home. I use my homelab to have a place to "just run things" like Plex and the whole host of other services that I either run or have written for my husband and I.
Really, I just wanna be able to use this to mess around, try new things, and turn the fruit of those experiments into blogposts like this one. Until very recently, everything in my homelab ran NixOS. A friend of mine has been goading me into trying Kubernetes again, and in a moment of weakness, I decided to see how bad the situation was to get Kubernetes running on my own hardware at home.
kos-mos, a small server that I use for running some CI things and periphery services. It has 32 GB of ram and a Core i5-10600.ontos, identical tokos-mosbut with an RTX 2060 6 GB.logos, identical tokos-mosbut with a RTX 3060 12 GB.pneuma, my main shellbox and development machine. It is a handbuilt tower PC with 64 GB of ram and a Ryzen 9 5900X. It has a GPU (AMD RX5700 non-XT w/8GB of vram) because the 5900X doesn't have integrated graphics. It has a bunch of random storage devices in it. It also handles the video transcoding for xesite video uploads.itsuki, the NAS. It has all of our media and backups on it. It runs Plex and a few other services, mostly managed by docker compose. It has 16 GB of ram and a Core i5-10600.chrysalis, an old Mac Pro from 2013 that I mostly use as my Prometheus server. It has 32 GB of ram and a Xeon E5-1650. It also runs the IRC bot[Mara]in#xeservon Libera.chat (it announces new posts on my blog). It's on its last legs in multiple ways, but it works for now. I've been holding off on selling it because I won it in a competition involving running an IRC network in Docker containers. Sentimental value is a bitch, eh?
Of these machines, kos-mos is the easiest to deal with because it normally doesn't have any services dedicated to it. In the past, I had to move some workloads off of it for various reasons.
I have no plans to touch my shellbox or the NAS, those have complicated setups that I don't want to mess with. I'm okay with my shellbox being different because that's where I do a lot of development and development servers are almost always vastly different from production servers. I'm also scared to touch the NAS because that has all my media on it and I don't want to risk losing it. It has more space than the rest of the house combined.
A rebuild of the homelab is going to be a fair bit of work. I'm going to have to take this one piece at a time and make sure that I don't lose anything important.
This post isn't going to be like my other posts. This is a synthesis of a few patron-exclusive notes that described my steps in playing with options and had my immediate reactions as I was doing things. If you want to read those brain-vomit notes, you can support me on Patreon and get access to them.
When I was considering what to do, I had a few options in mind:
- Rocky Linux (or even Oracle Linux) with Ansible
- Something in the Universal Blue ecosystem
- Fedora CoreOS
- K3os
- Talos Linux
- Giving up on the idea of having a homelab, throwing all of my computers into the sun (or selling them on Kijiji), and having a simpler life
I ran a poll on Mastodon to see what people wanted me to do. The results were overwhelmingly in favor of Rocky Linux. As an online "content creator", who am I to not give the people what they want?
Rocky Linux
Rocky Linux is a fork of pre-Stream CentOS. It aims to be a 1:1 drop-in replacement for CentOS and RHEL. It's a community-driven project that is sponsored by the Rocky Enterprise Software Foundation.
For various reasons involving my HDMI cable being too short to reach the other machines, I'm gonna start with chrysalis. Rocky Linux has a GUI installer and I can hook it up to the sideways monitor that I have on my desk. For extra fun, whenever the mac tries to display something on the monitor, the EFI framebuffer dances around until the OS framebuffer takes over.
https://files.xeiaso.net/video/2024/oneoff-mac-boot/index.m3u8
The weird part about chrysalis is that it's a Mac Pro from 2013. Macs of that vintage can boot normal EFI partitions and binaries, but they generally prefer to have your EFI partition be a HFS+ volume. This is normally not a problem because the installer will just make that weird EFI partition for you.
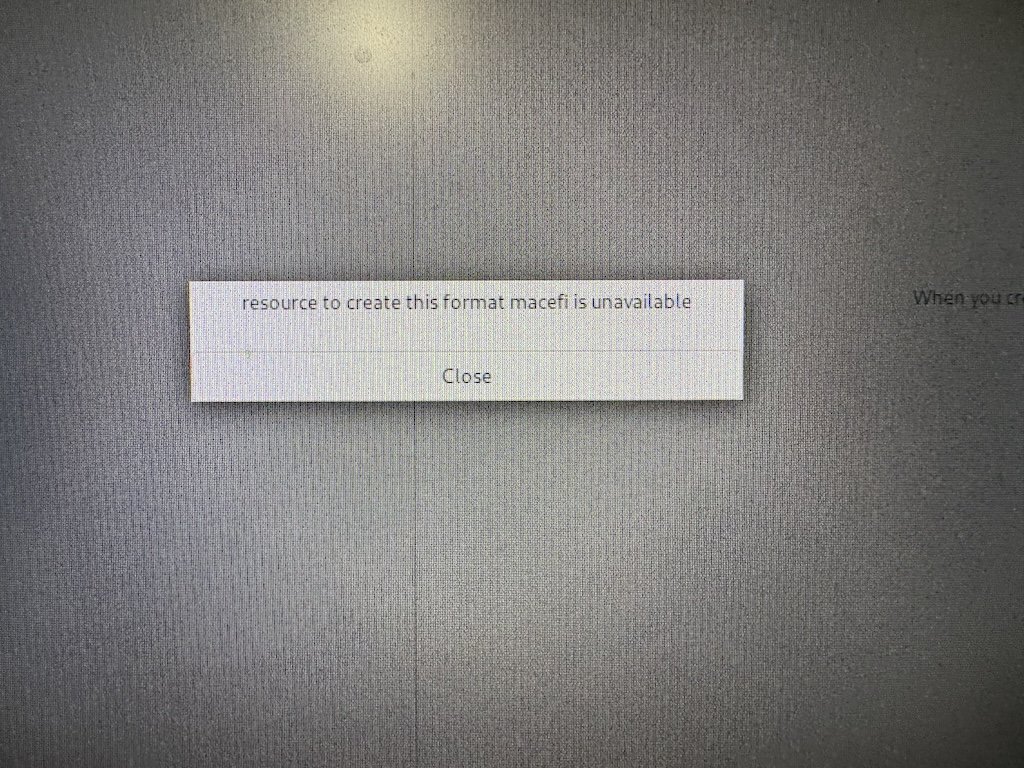
However, the Rocky Linux installer doesn't make that magic partition for you. They ifdeffed out the macefi installation flow because Red Hat ifdeffed it out.
As a result, you have to do a very manual install that looks something like this lifted from the Red Hat bug tracker:
- Boot Centos/RHEL 8 ISO Normally (I used 8.1 of each)
- Do the normal setup of network, packages, etc.
- Enter disk partitioning
- Select your disk
- At the bottom, click the "Full disk summary and boot loader" text
- Click on the disk in the list
- Click "Do not install boot loader"
- Close
- Select "Custom" (I didn't try automatic, but it probably would not create the EFI partition)
- Done in the top left to get to the partitioning screen
- Delete existing partitions if needed
- Click +
- CentOS 8: create /boot/efi mountpoint, 600M, Standard EFI partition
- RHEL 8: create /foo mountpoint, 600M, Standard EFI partition, then edit the partition to be on /boot/efi
- Click + repeatedly to create the rest of the partitions as usual (/boot, / swap, /home, etc.)
- Done
- During the install, there may be an error about the mactel package, just continue
- On reboot, both times I've let it get to the grub prompt, but there's no grub.cfg; not sure if this is required
- Boot off ISO into rescue mode
- Choose 1 to mount the system on /mnt/sysimage
- At the shell, chroot /mnt/sysimage
- Check on the files in /boot to make sure they exist: ls -l /boot/ /boot/efi/EFI/redhat (or centos)
- Run the create the grub.cfg file: grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- I got a couple reload ioctl errors, but that didn't seem to hurt anything
- exit
- Next reboot should be fine, and as mentioned above it'll reboot after SELinux labelling
So, that's a wash. In the process of figuring this out I also found out that when I wiped the drive, I took down my IRC bot (and lost the password, thanks A_Dragon for helping me recover that account). I'm going to have to fix that eventually.
I ended up moving the announcer IRC bot to be a part of within.website/x/cmd/mimi. mimi is a little bot that has claws into a lot of other things, including:
- Status page updates for the fly.io community Discord's #status channel
- Announcing new blogposts on #xeserv on libera.chat
- Google Calendar and its own Gmail account for a failed experiment to make a bot that could read emails forwarded to it and schedule appointments based on what a large language model parsed out of the email
Ansible
As a bonus round, let's see what it would look like to manage things with Ansible on Rocky Linux should I have been able to install Rocky Linux anyways. Ansible is a Red Hat product, so I expect that it would be the easiest thing to use to manage things.
Ansible is a "best hopes" configuration management system. It doesn't really authoritatively control what is going on, it merely suggest what should be going on. As such, you influence what the system does with "plays" like this:
- name: Full system update
dnf:
name: "*"
state: latest
This is a play that tells the system to update all of its packages with dnf. However, when I ran the linter on this, I got told I need to instead format things like this:
- name: Full system update
ansible.builtin.dnf:
name: "*"
state: latest
You need to use the fully qualified module name because you might install other collections that have the name dnf in the future. This kinda makes sense at a glance, I guess, but it's probably overkill for this usecase. However, it makes the lint errors go away and it is fixed mechanically, so I guess that's fine.
What's not fine is how you prevent Ansible from running the same command over and over. You need to make a folder full of empty semaphore files that get touched when the command runs:
- name: Xe's semaphore flags
ansible.builtin.shell: mkdir -p /etc/xe/semaphores
args:
creates: /etc/xe/semaphores
- name: Enable CRB repositories # CRB == "Code-Ready Builder"
ansible.builtin.shell: |
dnf config-manager --set-enabled crb
touch /etc/xe/semaphores/crb
args:
creates: /etc/xe/semaphores/crb
And then finally you can install a package:
- name: Install EPEL repo lists
ansible.builtin.dnf:
name: "epel-release"
state: present
This is about the point where I said "No, I'm not going to deal with this". I haven't even created user accounts or installed dotfiles yet, I'm just trying to install a package repository so that I can install other packages.
So I'm not going with Ansible (or likely any situation where Ansible would be required), even on the machines where installing Rocky Linux works without having to enter GRUB rescue shell purgatory.
CoreOS
Way back when my career was just starting, CoreOS was released. CoreOS was radical and way ahead of its time. Instead of having a mutable server that you can SSH into and install packages at will on, CoreOS had the view that thou must put all your software into Docker containers and run them that way. This made it impossible to install new packages on the server, which they considered a feature.
I loved using CoreOS when I could because of one part that was absolutely revolutionary: Fleet. Fleet was a distributed init system that let you run systemd services somewhere, but you could care where it ran when you needed to. Imagine a world where you could just spin your jobs somewhere, that was Fleet.
The really magical part about Fleet was the fact that it was deeply integrated into the discovery mechanism of CoreOS. Want 4 nodes in a cluster? Provision them with the same join token and Fleet would just figure it out. Newly provisioned nodes would also accept new work as soon as it was issued.
And then it became irrelevant in the face of Kubernetes after CoreOS got bought out by Red Hat and then IBM bought out Red Hat.
Also, "classic" CoreOS is no more, but its spirit lives on in the form of Fedora CoreOS, which is like CoreOS but built on top of rpm-ostree. The main difference between Fedora CoreOS and actual CoreOS is that Fedora CoreOS lets you install additional packages on the system.
Fedora CoreOS
For various reasons involving divine intervention, I'm going to be building a few of my own RPM packages. I'm also going to be installing other third party programs on top of the OS, such as yeet.
Fedora CoreOS is a bit unique because you install it by declaring the end result of the system, baking that into an ISO, and then plunking that onto a flashdrive to assimilate the machine. If you are using it from a cloud environment, then you plunk your config into the "user data" section of the instance and it will happily boot up with that configuration.
This is a lot closer to the declarative future I want, with the added caveat that changing the configuration of a running system is a bit more involved than just SSHing into the machine and changing a file. You have to effectively blow away the machine and start over.
I want to build this on top of rpm-ostree because I want to have the best of both worlds: an immutable system that I can still install packages on. This is an absolute superpower and I want to have it in my life. Realistically I'm gonna end up installing only one or two packages on top of the base system, but those one or two packages are gonna make so many things so much easier. Especially for my WireGuard mesh so I can route the pod/service subnets in my Kubernetes cluster.
As a more practical example of how rpm-ostree, let's take a look at Bazzite Linux. Bazzite is a spin of Fedora Silverblue (desktop Fedora built on top of rpm-ostree) that has the Steam Deck UI installed on top of it. This turns devices like the ROG Ally into actual game consoles instead of handheld gaming PCs.
In Bazzite, rpm-ostree lets you layer on additional things like the Fanatec steering wheel drivers and wheel managers like Oversteer. This allows you to add optional functionality without having to worry about breaking the base system. Any time updates are installed, rpm-ostree will layer Oversteer on top of it for you so that you don't have to worry about it.
This combined with my own handrolled RPMs with yeet means that I could add software to my homelab nodes (like I have with Nix/NixOS) without having to worry about it being rebuilt from scratch or its distribution. This is a superpower that I want to keep in my life.
It's not gonna be as nice as the Nix setup, but something like this:
["amd64", "arm64"].forEach((goarch) =>
rpm.build({
name: "yeet",
description: "Yeet out actions with maximum haste!",
homepage: "https://within.website",
license: "CC0",
goarch,
build: (out) => {
go.build("-o", `${out}/usr/bin/`);
},
})
);
is so much easier to read and manage than it is to do with RPM specfiles. It really does get closer to what it's like to use Nix.
I'd also need to figure out how to fix Gitea's RPM package serving support so that it signs packages for me, but would be solvable. Most of the work is already done, I'd just need to take over the PR and help push it over the finish line.
Installing Fedora CoreOS
The method I'm going to be using to install Fedora CoreOS is to use coreos-installer to build an ISO image with a configuration file generated by butane.
To make things extra fun, I'm writing this on a Mac, which means I will need to have a Fedora environment handy to build the ISO because Fedora only ships Linux builds of coreos-installer and butane.
First, I needed to install Podman Desktop, which is like the Docker Desktop app except it uses the Red Hat Podman stack instead of the Docker stack. For the purposes of this article, they are functionally equivalent.
I made a new repo/folder and then started up a Fedora container:
podman run --rm -itv .:/data fedora:latest
I then installed the necessary packages:
dnf -y install coreos-installer butane ignition-validate
And then I copied over the template from the Fedora CoreOS k3s tutorial into chrysalis.bu. I edited it to have the hostname chrysalis, loaded my SSH keys into it, and then ran the script to generate a prebaked install ISO. I loaded it on a flashdrive and then stuck it into the same Mac Pro from the last episode.
It installed perfectly. I suspect that the actual Red Hat installer can be changed to just treat this machine as a normal EFI platform without any issues, but that is a bug report for another day. Intel Macs are quickly going out of support anyways, so it's probably not going to be the highest priority for then even if I did file that bug.
I got k3s up and running and then I checked the version number. My config was having me install k3s version 1.27.10, which is much older than the current version 1.30.0 "Uwubernetes". I fixed the butane config to point to the new version of k3s and then I tried to find a way to apply it to my running machine.
Yeah, about that. It turns out that Fedora CoreOS is very much on the side of "cattle, not pets" when it comes to datacenter management. The Fedora CoreOS view is that any time you need to change out the Ignition config, you should reimage the machine. This makes sense for a lot of hyperconverged setups where this is as simple as pushing a button and waiting for it to come back.
However, my homelab is many things, but it isn't a hyperconverged datacenter setup. It's where I fuck around so I can find out (and then launder that knowledge through you to the rest of the industry for Patreon money and ad impressions). If I want to adopt an OS in the homelab, I need the ability to change my mind without having to burn four USB drives and reflash my homelab.
This was a bummer. I'm gonna have to figure out something else to get Kubernetes up and running for me.
Other things I evaluated and ended up passing on
I was told by a coworker that k3OS is a great way to have a "boot to Kubernetes" environment that you don't have to think about. This is by the Rancher team, which I haven't heard about in ages since I played with RancherOS way back in the before times.
RancherOS was super wild for its time. It didn't have a package manager, it had the Docker daemon. Two Docker daemons in fact, one for the "system" docker daemon that handled things like TTY sessions, DHCP addresses, device management, system logs, and the like. The other Docker daemon was for the userland, which was where you ran your containers.
I tried to get K3os up and running, but then I found out that it's deprecated. That information isn't on the website, it's on the getting started documentation. It's apparently replaced by Elemental, which seems to be built on top of OpenSUSE (kinda like how Fedora CoreOS is built on Fedora).
I'm gonna pass on this for now. Maybe in the future.
The Talos Principle
Straton of Stageira once argued that the mythical construct Talos (an automaton that experienced qualia and had sapience) proved that there was nothing special about mankind. If a product of human engineering could have the same kind of qualia that people do, then realistically there is nothing special about people when compared to machines.
To say that Talos Linux is minimal is a massive understatement. It only has literally 12 binaries in it. I've been conceptualizing it as "what if gokrazy was production-worthy?".
My main introduction to it was last year at All Systems Go! by a fellow speaker. I'd been wanting to try something like this out for a while, but I haven't had a good excuse to sample those waters until now. It's really intriguing because of how damn minimal it is.
So I downloaded the arm64 ISO and set up a VM on my MacBook to fuck around with it. Here's a few of the things that I learned in the process:
UTM has two modes it can run a VM in. One is "Apple Virtualization" mode that gives you theoretically higher performance at the cost of less options when it comes to networking (probably because Hypervisor.framework has less knobs available to control the VM environment). In order to connect the VM to a shared network (so you can poke it directly with talosctl commands without needing overlay VPNs or crazy networking magic like that), you need to create it without "Apple Virtualization" checked. This does mean you can't expose Rosetta to run amd64 binaries (and performance might be theoretically slower in a way you can't perceive given the minimal linux distros in play), but that's an acceptable tradeoff.
Talos Linux is completely declarative for the base system and really just exists to make Kubernetes easier to run. One of my favorite parts has to be the way that you can combine different configuration snippets together into a composite machine config. Let's say you have a base "control plane config" in controlplane.yaml and some host-specific config in hosts/hostname.yaml. Your talosctl apply-config command would look like this:
talosctl apply-config -n kos-mos -f controlplane.yaml -p @patches/subnets.yaml -p @hosts/kos-mos.yaml
This allows your hosts/kos-mos.yaml file to look like this:
cluster:
apiServer:
certSANs:
- 100.110.6.17
machine:
network:
hostname: kos-mos
install:
disk: /dev/nvme0n1
which allows me to do generic settings cluster-wide and then specific settings for each host (just like I have with my Nix flakes repo). For example, I have a few homelab nodes with nvidia GPUs that I'd like to be able to run AI/large langle mangle tasks on. I can set up the base config to handle generic cases and then enable the GPU drivers only on the nodes that need them.
The Talosctl Dashboard
I just have to take a moment to gush about the talosctl dashboard command. It's a TUI interface that lets you see what your nodes are doing. When you boot a metal Talos Linux node, it opens the dashboard by default so you can watch the logs as the system wakes up and becomes active.
When you run it on your laptop, it's as good as if not better than having SSH access to the node. All the information you could want is right there at a glance and you can connect to mulitple machines at once. Just look at this:
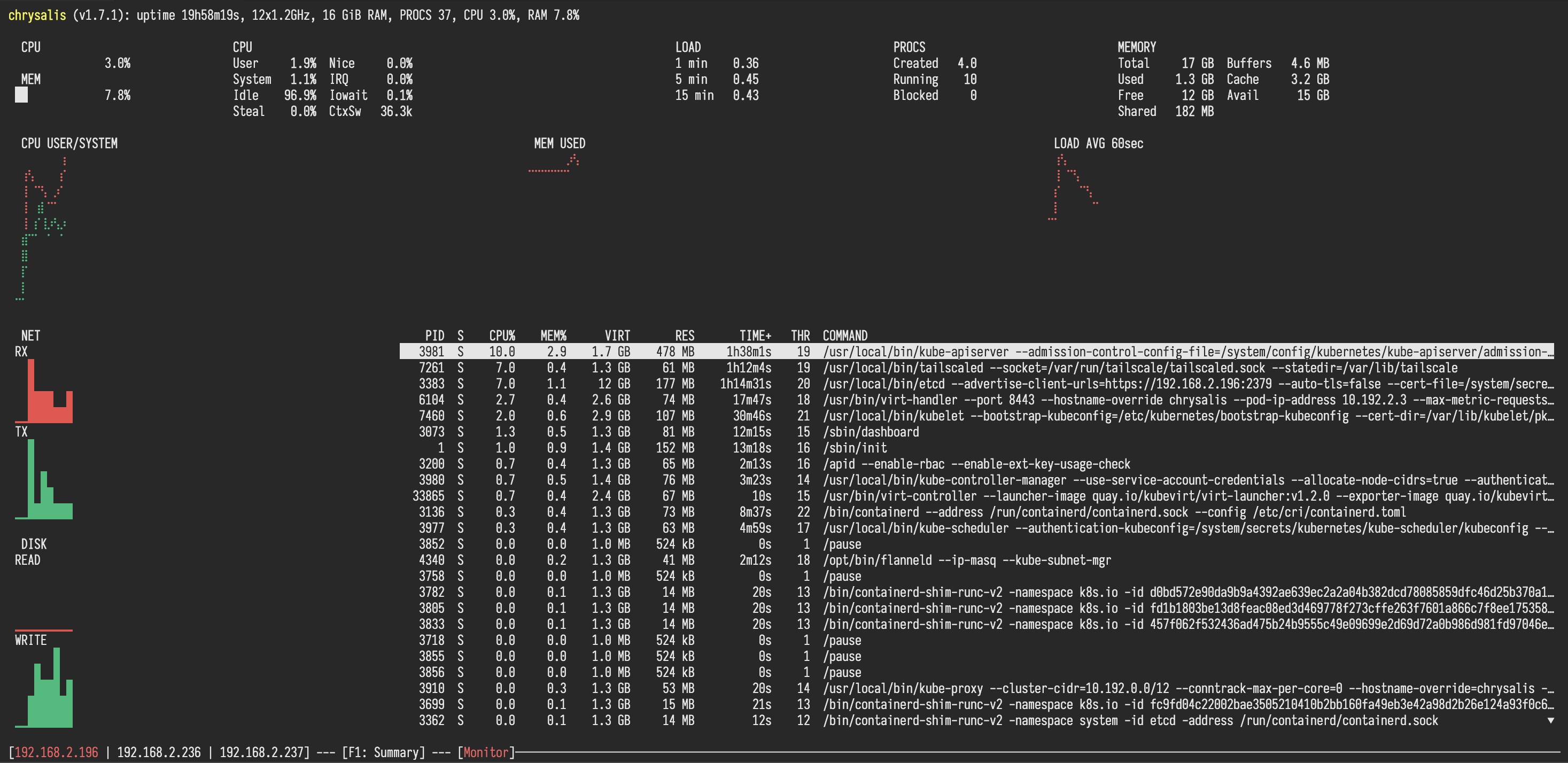
Those three nodes can be swapped between by pressing the left and right arrow keys. It's the best kind of simple, the kind that you don't have to think about in order to use it. No documentation needed, just run the command and go on instinct. I love it.
You can press F2 to get a view of the processes, resource use, and other errata. It's everything you could want out of htop, just without the ability to run Doom.
Making myself a Kubernete
Talos Linux is built to do two things:
- Boot into Linux
- Run Kubernetes
That's it. It's beautifully brutalist. I love it so far.
I decided to start with kos-mos arbitrarily. I downloaded the ISO, tried to use balenaEtcher to flash it to a USB drive and then windows decided that now was the perfect time to start interrupting me with bullshit related to Explorer desperately trying to find and mount USB drives.
I was unable to use balenaEtcher to write it, but then I found out that Rufus can write ISOs to USB drives in a way that doesn't rely on Windows to do the mounting or writing. That worked and I had kos-mos up and running in short order.
After bootstrapping etcd and exposing the subnet routes, I made an nginx deployment with a service as a "hello world" to ensure that things were working properly. Here's the configuration I used:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app.kubernetes.io/name: nginx
spec:
replicas: 3
selector:
matchLabels:
app.kubernetes.io/name: nginx
template:
metadata:
labels:
app.kubernetes.io/name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app.kubernetes.io/name: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
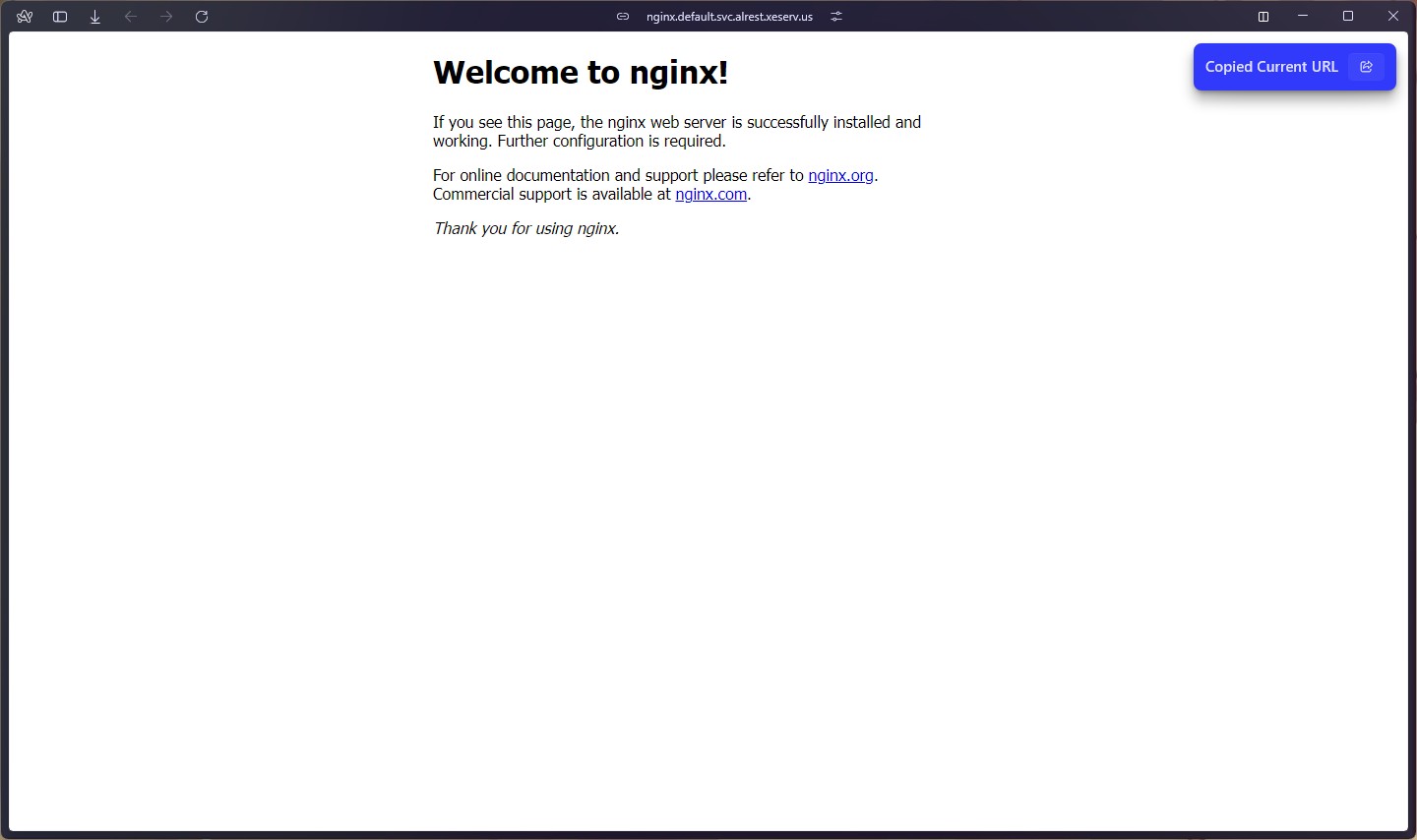
Once this is up, you're golden. You can start deploying more things to your cluster and then they can talk to eachother. One of the first things I deployed was a Reddit/Discord bot that I maintain for a community I've been in for a long time. It's a simple stateless bot that only needs a single deployment to run. You can see its source code and deployment manifest here.
The only weird part here is that I needed to set up secrets for handling the bot's Discord webhook. I don't have a secret vault set up (looking onto setting up the 1password one out of convenience because I already use it at home), so I yolo-created the secret with kubectl create secret generic sapientwindex --from-literal=DISCORD_WEBHOOK_URL=https://discord.com/api/webhooks/1234567890/ABC123 and then mounted it into the pod as an environment variable. The relevant yaml snippet is under the bot container's env key:
env:
- name: DISCORD_WEBHOOK_URL
valueFrom:
secretKeyRef:
name: sapientwindex
key: DISCORD_WEBHOOK_URL
This is a little more verbose than I'd like, but I understand why it has to be this way. Kubernetes is the most generic tool you can make, as such it has to be able to adapt to any workflow you can imagine. Kubernetes manifests can't afford to make too many assumptions, so they simply elect not to as much as possible. As such, you need to spell out all your assumptions by hand.
I'll get this refined in the future with templates or whatever, but for now my favorite part about it is that it works.
After I got that working, I connected some other nodes and I've ended up with this:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
chrysalis Ready control-plane 20h v1.30.0
kos-mos Ready control-plane 20h v1.30.0
ontos Ready control-plane 20h v1.30.0
The next big thing to get working is to get a bunch of operators working so that I can have my cluster dig its meaty claws into various other things.
What the hell is an operator anyways?
In Kubernetes land, an operator is a thing you install into your cluster that makes it integrate with another service or provides some functionality. For example, the 1Password operator lets you import 1Password data into your cluster as Kubernetes secrets. It's effectively how you extend Kubernetes to do more things with the same Kubernetes workflow you're already used to.
One of the best examples of this is the 1Password operator I mentioned. It's how I'm using 1Password to store secrets for my apps in my cluster. I can then edit them with the 1Password app on my PC or MacBook and the relevant services will restart automatically with the new secrets.
So I installed the operator with Helm and then it worked the first time. I was surprised, given how terrible Helm is in my experience.
The only hard part I ran into was that it wasn't obvious how I should assemble the reference strings for 1Password secrets. When you create the 1Password secret syncing object, it looks like this:
apiVersion: onepassword.com/v1
kind: OnePasswordItem
metadata:
name: sapientwindex
spec:
itemPath: "vaults/lc5zo4zjz3if3mkeuhufjmgmui/items/cqervqahekvmujrlhdaxgqaffi"
This tells the operator to create a secret named sapientwindex in the default namespace with the item path vaults/lc5zo4zjz3if3mkeuhufjmgmui/items/cqervqahekvmujrlhdaxgqaffi. The item path is made up of the vault ID (lc5zo4zjz3if3mkeuhufjmgmui) and the item ID (cqervqahekvmujrlhdaxgqaffi). I wasn't sure how to get these in the first place, but I found the vault ID with the op vaults list command and then figured out you can enable right-clicking in the 1Password app to get the item ID.
To enable this, go to Settings -> Advanced -> Show debugging tools in the 1Password app. This will let you right-click any secret and choose "Copy item UUID" to get the item ID for these secret paths.
This works pretty great, I'm gonna use this extensively going forward. It's gonna be slightly painful at first, but once I get into the flow of this (and realistically write a generator that pokes the 1password cli to scrape this information more easily) it should all even out.
Trials and storage tribulations
As I said at the end of my most recent conference talk, storage is one of the most annoying bullshit things ever. It's extra complicated with Talos Linux in particular because of how it uses the disk. Most of the disks of my homelab are Talos' "ephemeral state" partitions, which are used for temporary storage and wiped when the machine updates. This is great for many things, but not for persistent storage with PersistentVolumes/PersistntVolumeClaims.
I have tried the following things:
- Longhorn: a distributed block storage thing for Kubernetes by the team behind Rancher. It's pretty cool, but I got stuck at trying to get it actually running on my cluster. The pods were just permanently stuck in the
Pendingstate due to etcd not being able to discover itself. - OpenEBS: another distributed block storage thing for Kubernetes by some team of some kind. It claims to be the most widely used storage thing for Kubernetes, but I couldn't get it to work either.
Among the things I've realized when debugging this is that no matter what, many storage things for Kubernetes will hardcode the cluster DNS name to be cluster.local. I made my cluster use the DNS name alrest.xeserv.us following the advice of one of my SRE friends to avoid using "fake" DNS names as much as possible . This has caused me no end of trouble, as many things in the Kubernetes ecosystem assume that the cluster DNS name is cluster.local. It turns out that many Kubernetes ecosystem tools hard-assume the DNS name because the CoreDNS configs in many popular Kubernetes platforms (like AWS EKS, Azure whatever-the-heck, and GKE) have broken DNS configs that make relative DNS names not work reliably. As a result, people have hardcoded the DNS name to cluster.local in many places in both configuration and code.
Fixing this was easy, I had to edit the CoreDNS ConfigMap to look like this:
data:
Corefile: |-
.:53 {
errors
health {
lameduck 5s
}
ready
log . {
class error
}
prometheus :9153
kubernetes cluster.local alrest.xeserv.us in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
I prepended the cluster.local "domain name" to the kubernetes block. Then I deleted the CoreDNS pods in the kube-system namespace and they were promptly restarted with the new configuration. This at least got me to the point where normal DNS things worked again.
However, this didn't get Longhorn working. The manager container was just stuck trying to get created. Turns out the solution was really stupid and I want to explain what's going on here so that you can properly commiserate with me over the half a day I spent trying to get this working.
Talos Linux sets a default security policy that blocks the Longhorn manager from running. This is because the Longhorn manager runs as root and Talos Linux is paranoid about security. In order to get Longhorn running, I had to add the following annotations to the Longhorn namespace:
apiVersion: v1
kind: Namespace
metadata:
name: longhorn-system
labels:
pod-security.kubernetes.io/enforce: privileged
pod-security.kubernetes.io/enforce-version: latest
pod-security.kubernetes.io/audit: privileged
pod-security.kubernetes.io/audit-version: latest
pod-security.kubernetes.io/warn: privileged
pod-security.kubernetes.io/warn-version: latest
After you do this, you need to delete the longhorn-deployer Pod and then wait about 10-15 minutes for the entire system to converge. For some reason it doesn't automatically restart when labels are changed, but that is very forgiveable given how many weird things are at play with this ecosystem. Either way, getting this working at all was a huge relief.
Once Longhorn starts up, you can create a PersistentVolumeClaim and attach it to a pod:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-volv-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 256Mi
---
apiVersion: v1
kind: Pod
metadata:
name: volume-test
namespace: default
spec:
restartPolicy: Always
containers:
- name: volume-test
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
livenessProbe:
exec:
command:
- ls
- /data/lost+found
initialDelaySeconds: 5
periodSeconds: 5
volumeMounts:
- name: vol
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: vol
persistentVolumeClaim:
claimName: longhorn-volv-pvc
Longhorn ended up working, so I set up backups to Tigris and then I plan to not think about it until I need to. The only catch is that I need to label every PersistentVolumeClaim with recurring-job-group.longhorn.io/backup: enabled to make my backup job run:
apiVersion: longhorn.io/v1beta1
kind: RecurringJob
metadata:
name: backup
namespace: longhorn-system
spec:
cron: "0 0 * * *"
task: "backup"
groups:
- default
retain: 4
concurrency: 2
Hopefully I won't need to think about this for a while. At its best, storage is invisible.
The factory cluster must grow
I dug logos out of mothballs and then I plugged in the Talos Linux USB. I then ran the logos command to install Talos Linux on the machine. It worked perfectly and I had a new homelab node up and running in no time. All I had to do was:
- Get it hooked up to Ethernet and power
- Boot it off of the Talos Linux USB stick
- Apply the config with
talosctlfrom my macbook - Wait for it to reboot and everything to green up in
kubectl
That's it. This is what every homelab OS should strive to be.
I also tried to add my Win600 to the cluster, but I don't think Talos supports wi-fi. I'm asking in the Matrix channel and in a room full of experts. I was able to get it to connect to ethernet over USB in a hilariously jankriffic setup though:

I seriously can't believe this works. It didn't work well enough to stay in production, but it's worth a laugh or two at least. I ended up removing this node so that I can have floor space back. I'll have to figure out how to get it on the network properly later, maybe after DevOpsDays KC.
ingressd and related fucking up
I was going to write about a super elegant hack that I'm doing to get ingress from the public internet to my homelab here, but I fucked up again and I potentially got to do etcd surgery.
The hack I was trying to do was creating a userspace wireguard network for handling HTTP/HTTPS ingress from the public internet. I chose to use the network 10.255.255.0/24 for this (I had a TypeScript file to configure the WireGuard keys and everything). Apparently Talos Linux configured etcd to prefer anything in 10.0.0.0/8 by default. This has lead to the following bad state:
$ talosctl etcd members -n 192.168.2.236
NODE ID HOSTNAME PEER URLS CLIENT URLS LEARNER
192.168.2.236 3a43ba639b0b3ec3 chrysalis https://10.255.255.16:2380 https://10.255.255.16:2379 false
192.168.2.236 d07a0bb98c5c225c kos-mos https://10.255.255.17:2380 https://192.168.2.236:2379 false
192.168.2.236 e78be83f410a07eb ontos https://10.255.255.19:2380 https://192.168.2.237:2379 false
192.168.2.236 e977d5296b07d384 logos https://10.255.255.18:2380 https://192.168.2.217:2379 false
This is uhhh, not good. The normal strategy for recovering from an etcd split brain involves stopping etcd on all nodes and then recovering one of them, but I can't do that because talosctl doesn't let you stop etcd:
$ talosctl service etcd -n 192.168.2.196 stop
error starting service: 1 error occurred:
* 192.168.2.196: rpc error: code = Unknown desc = service "etcd" doesn't support stop operation via API
When you get etcd into this state, it is generally very hard to convince it otherwise without doing database surgery and suffering the pain of having fucked it up. Fixing this is a very doable process, but I didn't really wanna deal with it.
I ended up blowing away the cluster and starting over. I tried using TESTNET (192.0.2.0/24) for the IP range but ran into issues where my super hacky userspace WireGuard code wasn't working right. I gave up at this point and ended up using my existing WireGuard mesh for ingress. I'll have to figure out how to do this properly later.
ingressd ended up becoming a simple TCP proxy with added PROXY protocol support so that ingress-nginx could get the right source IP addresses. It's nothing to write home about, but it's my simple TCP proxy that I probably could have used something off the shelf for.
Using ingressd (why would you do this to yourself)
If you want to install ingressd for your cluster, here's the high level steps:
- Gather the secret keys needed for this terraform manifest (change the domain for Route 53 to your own domain): https://github.com/Xe/x/blob/master/cmd/ingressd/tf/main.tf
- Run
terraform applyin the directory with the above manifest - Go a level up and run
yeetto build the ingressd RPM - Install the RPM on your ingressd node
- Create the file
/etc/ingressd/ingressd.envwith the following contents:
HTTP_TARGET=serviceIP:80
HTTPS_TARGET=serviceIP:443
This assumes you are subnet routing your Kubernetes node and service network over your WireGuard mesh of choice. If you are not doing that, you can't use ingressd.
Also make sure to run the magic firewalld unbreaking commands:
firewall-cmd --zone=public --add-service=http
firewall-cmd --zone=public --add-service=https
It's always DNS
Now that I have ingress working, it's time for one of the most painful things in the universe: DNS. Since I've used Kubernetes last, External DNS is now production-ready. I'm going to use it to manage the DNS records for my services.
In typical Kubernetes fashion, it seems that it has gotten incredibly complicated since the last time I used it. It used to be fairly simple, but now installing it requires you to really consider what the heck you are doing. There's also no Helm chart, so you're really on your own.
After reading some documentation, I ended up on the following Kubernetes manifest: external-dns.yaml. So that I can have this documented for me as much as it is for you, here is what this does:
- Creates a namespace
external-dnsforexternal-dnsto live in. - Creates the
external-dnsCustom Resource Definitions (CRDs) so that I can make DNS records manually with Kubernetes objects should the spirit move me. - Creates a service account for
external-dns. - Creates a cluster role and cluster role binding for
external-dnsto be able to read a small subset of Kubernetes objects (services, ingresses, and nodes, as well as its custom resources). - Creates a 1Password secret to give
external-dnsRoute53 god access. - Creates two deployments of
external-dns:- One for the CRD powered external DNS to weave DNS records with YAML
- One to match on newly created ingress objects and create DNS records for them
If I ever need to create a DNS record for a service, I can do so with the following YAML:
apiVersion: externaldns.k8s.io/v1alpha1
kind: DNSEndpoint
metadata:
name: something
spec:
endpoints:
- dnsName: something.xeserv.us
recordTTL: 180
recordType: TXT
targets:
- "We're no strangers to love"
- "You know the rules and so do I"
- "A full commitment's what I'm thinking of"
- "You wouldn't get this from any other guy"
- "I just wanna tell you how I'm feeling"
- "Gotta make you understand"
- "Never gonna give you up"
- "Never gonna let you down"
- "Never gonna run around and hurt you"
- "Never gonna make you cry"
- "Never gonna say goodbye"
- "Never gonna tell a lie and hurt you"
Hopefully I'll never need to do this, but I bet that something will make me need to make a DNS TXT record at some point, and it's probably better to have that managed in configuration management somehow.
cert-manager
Now that there's ingress from the outside world and DNS records for my services, it's time to get HTTPS working. I'm going to use cert-manager for this. It's a Kubernetes native way to manage certificates from Let's Encrypt and other CAs.
Unlike nearly everything else in this process, installing cert-manager was relatively painless. I just had to install it with Helm. I also made Helm manage the Custom Resource Definitions, so that way I can easily upgrade them later.
The only gotcha here is that there's annotations for Ingresses that you need to add to get cert-manager to issue certificates for them. Here's an example:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kuard
annotations:
cert-manager.io/cluster-issuer: "letsencrypt-prod"
spec:
# ...
This will make cert-manager issue a certificate for the kuard ingress using the letsencrypt-prod issuer. You can also use letsencrypt-staging for testing. The part that you will fuck up is that the documentation mixes ClusterIssuer and Issuer resources and annotations. Here's what my Let's Encrypt staging and prod issuers look like:
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging
spec:
acme:
# You must replace this email address with your own.
# Let's Encrypt will use this to contact you about expiring
# certificates, and issues related to your account.
email: user@example.com
server: https://acme-staging-v02.api.letsencrypt.org/directory
privateKeySecretRef:
# Secret resource that will be used to store the account's private key.
name: letsencrypt-staging-acme-key
solvers:
- http01:
ingress:
ingressClassName: nginx
---
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod
spec:
acme:
# You must replace this email address with your own.
# Let's Encrypt will use this to contact you about expiring
# certificates, and issues related to your account.
email: user@example.com
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
# Secret resource that will be used to store the account's private key.
name: letsencrypt-prod-acme-key
solvers:
- http01:
ingress:
ingressClassName: nginx
These ClusterIssuers are what the cert-manager.io/cluster-issuer: annotation in the ingress object refers to. You can also use Issuer resources if you want to scope the issuer to a single namespace, but realistically I know you're lazier than I am so you're going to use ClusterIssuer.
The flow of all of this looks kinda complicated, but you can visualize it with this handy diagram:

Breaking this down, let's assume I've just created this Ingress resource:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kuard
annotations:
cert-manager.io/cluster-issuer: "letsencrypt-prod"
spec:
ingressClassName: nginx
tls:
- hosts:
- kuard.xeserv.us
secretName: kuard-tls
rules:
- host: kuard.xeserv.us
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kuard
port:
name: http
When I create this Ingress with the cluster-issuer annotation, it's discovered by both external-dns and cert-manager. external-dns creates DNS records in Route 53 (and tracks them using DynamoDB). At the same time, cert-manager creates a Cert resource for the domains I specified in the in the spec.tls.hosts field of my Ingress. The Cert resource discoveres that the secret kuard-tls has no valid certificate in it, so it creates an Order for a new certificate. The Order creates a Challenge by poking Let's Encrypt to get the required token and then configures its own Ingress to handle the HTTP-01 strategy.
Once it's able to verify that it can pass the Challenge locally (this requires external-dns to finish pushing DNS routes and for DNS to globally converge, but usually happens within a minute), it asks Let's Encrypt to test it. Once Let's Encrypt passes the test, it signs my certificate, the Challenge Ingress is deleted, the signed certificate is saved to the right Kubernetes secret, the Order is marked as fulfilled, the Cert is marked ready, and nginx is reloaded to point to that newly minted certificate.
Shipping the lab
At this point, my lab is stable, useful, and ready for me to put jobs on it. I have:
- A cluster of four machines running Talos Linux that I can submit jobs to with
kubectl - Persistent storage with Longhorn
- Backups of said persistent storage to Tigris
- Ingress from the public internet with
ingressdand crimes - DNS records managed by
external-dns - HTTPS certificates managed by
cert-manager
And this all adds up to a place where I can just throw jobs at and get the confidence that they will run. I'm going to be using this to run a bunch of other things that have previously been spread across a bunch of VPSes that I don't want to pay for anymore. Even though they are an excellent tax break right now.
The parts of a manifest for my homelab
When I deploy things to my homelab cluster, I can divide them into three basic classes:
- Automation/bots that don't expose any API or web endpoints
- Internal services that do expose API or web endpoints
- Public-facing services that should be exposed to the public internet
Automation/bots are the easiest. In the ideal case all I need is a Deployment and a Secret to hold the API keys to poke external services. For an example of that, see within.website/x/cmd/sapientwindex.
Internal services get a little bit more complicated. Depending on the service in question, it'll probably get:
- A Namespace to hold everything
- A PersistentVolumeClaim for holding state (SQLite, JSONMutexDB, etc.)
- A Secret or two for the various private/API keys involved in the process
- A Deployment with one or more containers that actually runs that internal service's code
- A Service that exposes the internal ports to the cluster on well-known port numbers
For most internal services, this is more than good enough. If I need to poke it, I can do so by connecting to svcname.ns.svc.alrest.xeserv.us. It'd work great for a Minecraft server or something else like that.
However, I also do need to expose things to the public internet sometimes. When I need to do that, I define an Ingress that has the right domain name so the rest of the stack will just automatically make it work.
This gives me the ability to just push things to the homelab without fear. Once new jobs get defined, the rest of the stack will converge, order certificates, and otherwise make things Just Work™️. It's kinda glorious now that it's all set up.
What's next?
Here are the things I want to play with next:
- KubeVirt: I want to run some VMs on my cluster. This looks like it could be the basis for an even better waifud setup. All it's missing is a decent admin UI, which I can probably make with Tailwind and HTMX. The biggest thing I want to play with is live migration of VMs between nodes.
- I want to get a Minecraft server running on my cluster and figure out some way to make it accessible to my patrons. I have no idea how I'll go about doing the latter, but I'm sure I'll figure it out. Worst case I think one of you nerds in the (patron-only) Discord has some ideas.
- I want to resurrect kubermemes for generating my app deployments. I've had a lot of opinions change since I wrote that so many years ago, but overall the shape of my deployments is going to be "small file with some resource requests" that compiles into "YAML means 'Yeah, A Massive List of stuff'".
- I may also want to get AI stuff running on Talos Linux. I have two GPUs in that cluster and kinda want to have stable diffusion at home again. It'll be a good way to get back into the swing of things with AI stuff.
- ??? who knows what else will come up through my binges into weird GitHub projects and Hacker News.
I'm willing to declare my homelab a success at this point. It's cool that I can spread the load between my machines so much more cleanly now. I'm excited to see what I can do with this, and I hope that you are excited that you get more blog posts out of it.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: Homelab, RockyLinux, FedoraCoreOS, TalosLinux, Kubernetes, Ansible, Longhorn, Nginx, CertManager, ExternalDNS